Hello everybody,
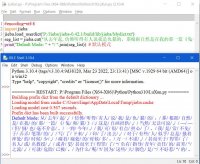
This is the first time I use Python, so I am a complete newie. After having installed Jieba for Python, I have run into a weird problem. So far, I have just managed to do what you can see in the first snapshot (Python-Jieba (1).jpg)
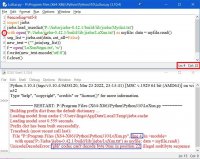
Encouraged by that, I tried to segment the same text by opening a text file (utf-8 no BOM), but got this message (please, see Python-Jieba (2).jpg):
" File "P:\Program Files (X64-X86)\Python\Python310\LuXun.py", line 4, in <module> with open('P:/Jieba/jieba-0.42.1/build/lib/jieba/LuXun.txt') as myfile: data = myfile.read() UnicodeDecodeError: 'gbk' codec can't decode byte 0xac in position 22: illegal multibyte sequence"
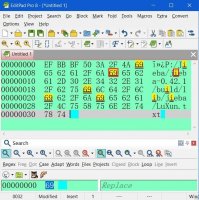
The "illegal multibyte sequence (byte 0xac)" happens to be the letter "i" that is in "line 4, in position 22". But the character code of that letter "i" is the same as the one for the other occurrences of "i" in that same line, mainly 0069 (Unicode (hex), Simp. Chinese GB (hex)). You can see that on the third snapshot (Python-Jieba (3).jpg).
As I said at the beginning, I am a complete newie in Python. Does someone have any idea about what I may be doing wrong?
Thank you for any comments and/or suggestions!
This is the first time I use Python, so I am a complete newie. After having installed Jieba for Python, I have run into a weird problem. So far, I have just managed to do what you can see in the first snapshot (Python-Jieba (1).jpg)
Encouraged by that, I tried to segment the same text by opening a text file (utf-8 no BOM), but got this message (please, see Python-Jieba (2).jpg):
" File "P:\Program Files (X64-X86)\Python\Python310\LuXun.py", line 4, in <module> with open('P:/Jieba/jieba-0.42.1/build/lib/jieba/LuXun.txt') as myfile: data = myfile.read() UnicodeDecodeError: 'gbk' codec can't decode byte 0xac in position 22: illegal multibyte sequence"
The "illegal multibyte sequence (byte 0xac)" happens to be the letter "i" that is in "line 4, in position 22". But the character code of that letter "i" is the same as the one for the other occurrences of "i" in that same line, mainly 0069 (Unicode (hex), Simp. Chinese GB (hex)). You can see that on the third snapshot (Python-Jieba (3).jpg).
As I said at the beginning, I am a complete newie in Python. Does someone have any idea about what I may be doing wrong?
Thank you for any comments and/or suggestions!