jurgen85
榜眼
I spent way too long trying various possible syntax combinations, and beyond the normal markdown we know and love, this is what I figured out so far:
I will note that those generic cross-references can do fine with any single one of those parameters, but the more of them you specify the better it matches. Lists start automatically at the first number in that particular list. Have you found anything else? In particular I don’t know how to properly tag examples as Chinese characters and pinyin, or maybe provide automatically switching trad/simp.
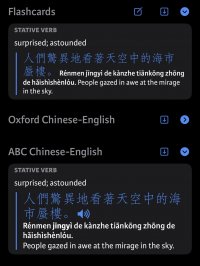
As close to a “real” entry I can get:

Code:
@@boxed text@@
@grammar label@
=specifying grammar label=
[generic cross-reference](pleco:e?tc=繁&sc=简&py=pin1yin1)
:::a secret?:::I will note that those generic cross-references can do fine with any single one of those parameters, but the more of them you specify the better it matches. Lists start automatically at the first number in that particular list. Have you found anything else? In particular I don’t know how to properly tag examples as Chinese characters and pinyin, or maybe provide automatically switching trad/simp.
As close to a “real” entry I can get:
Code:
@@A@@ @noun@
1. **bold**; evaluation @@MW@@ [次 ci4](pleco:e?tc=次&sc=次&py=ci4)
1. unrelated
1. surprise ^^small caps 3456789^^ 3456789
> 拼音例子
> pin1yin1 li4zi5
> pinyin example
@@B@@ @verb@ =literary=
95. test; evaluate
1. derail; *italic*
1. truly
1. the
1. ***bold italic***
1. nonsense