Hello,
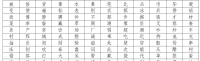
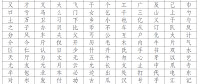
I thought some may be interested with this: I created this Python script to create a list of the individual characters from a flashcard set. It can either sort by pronunciation, or by stroke order (see attached example, reworked in excel for proper printing).
You need to export your set and name it flashtest.txt (no card or dictionary definition). It is also necessary to download Unihan_IRGSources.txt from https://www.unicode.org/Public/UCD/latest/ucd/ (the official unicode stroke count for each character).
The script can be found here: download
Hope you'll enjoy,
Pierre
I thought some may be interested with this: I created this Python script to create a list of the individual characters from a flashcard set. It can either sort by pronunciation, or by stroke order (see attached example, reworked in excel for proper printing).
You need to export your set and name it flashtest.txt (no card or dictionary definition). It is also necessary to download Unihan_IRGSources.txt from https://www.unicode.org/Public/UCD/latest/ucd/ (the official unicode stroke count for each character).
The script can be found here: download
Hope you'll enjoy,
Pierre