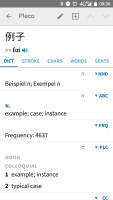
To help me focus on learning characters that are common, I like to know how frequently a given word or character I have looked at is. When I encounter a new character or word, I often have no idea whether it is worth the time to learn it. It would be great if Pleco just showed me that directly. Is there any plan to add this in the future? For me, I'd like a simple stack-ranked number (i.e. a unique frequency for each word, not like the Fenn frequency buckets), and it doesn't have to be super precise (i.e. I'm not too interested in the debates about how to measure frequency).
Ok, feature request aside, has anyone created a user dict that does this? If not, would others find this valuable? It seems like it would be a simple thing to do, and we could include multiple different frequency measures, HSK number, etc. I'd like to do it for multi-character words as well as single characters.
FWIW, so far, I've found that the Unihan database provides several unsatisfying measures: Frequency (http://www.unicode.org/reports/tr38/tr38-21.html#kFrequency), Fenn (http://www.unicode.org/reports/tr38/tr38-21.html#kFenn), Grade Level (http://www.unicode.org/reports/tr38/tr38-21.html#kGradeLevel) and Hanyu Pinlu (http://www.unicode.org/reports/tr38/tr38-21.html#kHanyuPinlu). I've used them all for awhile and Fenn is the closest to useful, and it is from 100 year old data.
Ok, feature request aside, has anyone created a user dict that does this? If not, would others find this valuable? It seems like it would be a simple thing to do, and we could include multiple different frequency measures, HSK number, etc. I'd like to do it for multi-character words as well as single characters.
FWIW, so far, I've found that the Unihan database provides several unsatisfying measures: Frequency (http://www.unicode.org/reports/tr38/tr38-21.html#kFrequency), Fenn (http://www.unicode.org/reports/tr38/tr38-21.html#kFenn), Grade Level (http://www.unicode.org/reports/tr38/tr38-21.html#kGradeLevel) and Hanyu Pinlu (http://www.unicode.org/reports/tr38/tr38-21.html#kHanyuPinlu). I've used them all for awhile and Fenn is the closest to useful, and it is from 100 year old data.