manishearth
Member
Hi!
I'm working on a custom dictionary that's based off of cross-dialectical data on Wiktionary, with the intent of making it easier to work with lects based on existing knowledge of a lect or using the existing dictionaries. Wiktionary has highly useful "dialectical synonyms" lists on various entries showing the common ways a different word is said (in other words, it has mappings from "standard written" form to the spoken form).
Here's what I have so far, generated for Mandarin/Cantonese/Taishanese and specifically for Beijing/Hong Kong/Taishan:

I'm currently using the "import text file" support that Pleco has for importing entries into a custom user dictionary. It's slow but it overall seems to work, and as far as I can tell this is the recommended way to do this¹.
For the imported entries to associate with existing entries (instead of creating new ones), I had to include pinyin pronunciations (or jyutping if the pinyin wasn't available) so that things would associate correctly (and I'm consistently using traditional characters; this is what Wiktionary does anyway, so there should not be ambiguity).
However, this still seems to be creating separate dictionary entries in some cases. For one, in some (but not all? It happens for 什麼 and 現在 but not 來 or 聽日) cases where the simplified and traditional forms differ it creates a separate entry:

(In the csv file, this has an entry "現在 xiànzài Pronunciation: Mandarin:...", though the tabs got converted to spaces when pasting here)
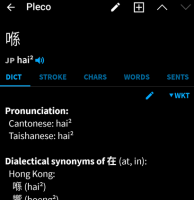
There's also some brokenness here:


(This has a csv entry "喺 {hai2} Pronunciation: Cantonese: ....")
Despite the jyutping tone mark not showing up in the search (this seems to be another bug²), it does show up on the entry itself, but for whatever reason the entry isn't associated with the existing one (maybe because my entry only has jyutping, not pinyin?)
I'm not really sure what to do here; it seems like there are a couple bugs or tricky bits in how Pleco associates imported dictionary entries with existing entries but it's not super clear, and I can't find much in the way of prior discussion. Help would be appreciated.
¹If there's a better way, I'm super down to try that instead. In the long run I plan to release an open source tool so that you can make these on your own (if you'd like to try it out now, feel free to post on my profile to ask for a specific set of lects and i can make you one). I'm also happy to help make this a part of the main app provided it can be done in a way that works with Wiktionary's CC-BY-SA licensing: it would be really cool if this could be a configurable dictionary the way the builtin Unicode/UNI dictionary is where you select the lects you care about and it only shows up on entries where that matters. Perhaps have a separate pronunciation and synonym dictionary.
²This bug has also hit me a bunch when importing flashcards from my vocab Google sheet with the "create new if not found" option enabled, which only has jyutping; the resultant entries show up without tone mark and look weird.
I'm working on a custom dictionary that's based off of cross-dialectical data on Wiktionary, with the intent of making it easier to work with lects based on existing knowledge of a lect or using the existing dictionaries. Wiktionary has highly useful "dialectical synonyms" lists on various entries showing the common ways a different word is said (in other words, it has mappings from "standard written" form to the spoken form).
Here's what I have so far, generated for Mandarin/Cantonese/Taishanese and specifically for Beijing/Hong Kong/Taishan:
I'm currently using the "import text file" support that Pleco has for importing entries into a custom user dictionary. It's slow but it overall seems to work, and as far as I can tell this is the recommended way to do this¹.
For the imported entries to associate with existing entries (instead of creating new ones), I had to include pinyin pronunciations (or jyutping if the pinyin wasn't available) so that things would associate correctly (and I'm consistently using traditional characters; this is what Wiktionary does anyway, so there should not be ambiguity).
However, this still seems to be creating separate dictionary entries in some cases. For one, in some (but not all? It happens for 什麼 and 現在 but not 來 or 聽日) cases where the simplified and traditional forms differ it creates a separate entry:
(In the csv file, this has an entry "現在 xiànzài Pronunciation: Mandarin:...", though the tabs got converted to spaces when pasting here)
There's also some brokenness here:
(This has a csv entry "喺 {hai2} Pronunciation: Cantonese: ....")
Despite the jyutping tone mark not showing up in the search (this seems to be another bug²), it does show up on the entry itself, but for whatever reason the entry isn't associated with the existing one (maybe because my entry only has jyutping, not pinyin?)
I'm not really sure what to do here; it seems like there are a couple bugs or tricky bits in how Pleco associates imported dictionary entries with existing entries but it's not super clear, and I can't find much in the way of prior discussion. Help would be appreciated.
¹If there's a better way, I'm super down to try that instead. In the long run I plan to release an open source tool so that you can make these on your own (if you'd like to try it out now, feel free to post on my profile to ask for a specific set of lects and i can make you one). I'm also happy to help make this a part of the main app provided it can be done in a way that works with Wiktionary's CC-BY-SA licensing: it would be really cool if this could be a configurable dictionary the way the builtin Unicode/UNI dictionary is where you select the lects you care about and it only shows up on entries where that matters. Perhaps have a separate pronunciation and synonym dictionary.
²This bug has also hit me a bunch when importing flashcards from my vocab Google sheet with the "create new if not found" option enabled, which only has jyutping; the resultant entries show up without tone mark and look weird.