JD
状元
I've used the Pleco OCR quite a bit and love it.
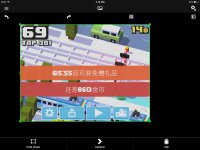
However, today I ran across an image that surprisingly gave me nothing at all.
It's a screenshot on my iPad from a game called "Crossy Road" with the language setting in the game set to Chinese.
Is the problem something to do with the white text on orange/red backgrounds? I tried flipping the setting for the white/black detection, but it doesn't help.
I literally get ZERO identification of any characters, unless I zoom in on a single character, in which case, I get something completely incorrect.
JD
EDIT: if I zoom the picture first and then put the bounding box around the small pieces of text, it does at least try to identify something...but it is still WAY off.
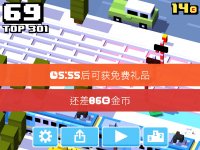
However, today I ran across an image that surprisingly gave me nothing at all.
It's a screenshot on my iPad from a game called "Crossy Road" with the language setting in the game set to Chinese.
Is the problem something to do with the white text on orange/red backgrounds? I tried flipping the setting for the white/black detection, but it doesn't help.
I literally get ZERO identification of any characters, unless I zoom in on a single character, in which case, I get something completely incorrect.
JD
EDIT: if I zoom the picture first and then put the bounding box around the small pieces of text, it does at least try to identify something...but it is still WAY off.
Attachments
Last edited: