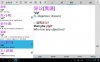
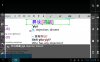
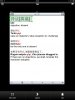
For fun, I loaded a screen shot of a dictionary entry. I have my system set for Simplified.
Is it true that the OCR won't do both simplified and traditional at the same time?
If so, is there a quick on-screen button/setting to toggle between the two?
OCR handled "yi4yi4" (simplified), but didn't get the traditional characters in square brackets.
Attached both source photo and OCR results.
SOURCE:
RESULT:
Is it true that the OCR won't do both simplified and traditional at the same time?
If so, is there a quick on-screen button/setting to toggle between the two?
OCR handled "yi4yi4" (simplified), but didn't get the traditional characters in square brackets.
Attached both source photo and OCR results.
SOURCE:
RESULT: