kasim
举人
Hello Pleco Community,
I am experiencing difficulties with importing the BKRS dictionary (the largest Chinese-Russian dictionary available) into the Pleco app and am hoping for some guidance. Here’s a breakdown of the issues and my setup:
1. Dictionary Structure and Import Settings(Settings before importing 1; 2.PNG, BKRS Sample Text.PNG, Settings that I have no clue what they change.PNG):
The BKRS file is structured with fields for Chinese characters, Pinyin, and definitions in Russian. From my attempts, I understand that the first field for Chinese characters should be set to ‘Simplified’, and the second field for Pinyin should be set as ‘Mandarin’. However, I encountered a problem with making the Russian definitions searchable. Initially setting the third field to ‘English’ didn't allow searches in Russian. Changing the setting to ‘Entry body' made it searchable but led to display issues across devices.
2. Display Inconsistencies Across Devices (3 screenshots - Display Inconsistencies iPad, iPad 2, iPhone):
When I configure the output to 'entry body', the dictionary appears differently on my devices. On my iPhone, dictionary entries show up as empty(), and on my iPad, Russian definitions incorrectly appear as Pinyin. It seems there may be a misinterpretation or mishandling of the data.
3. Potential Bugs with Column Settings:
I've noticed potential bugs in how settings are managed within the app. For example, changing the setting 'split to second field' resets previous settings for the columns back to default. Additionally, under 'output to field' set to Mandarin, the 'parse as' options for tone numbers and symbols seem to be reversed: selecting tone marks displays numbers and vice versa.
I am also including a video and screenshots of my settings to better illustrate these issues. I am also sending an extract from the dictionary for you guys to see whether the file is corrupted or has formatting issues(whole file is too big to upload on a website). I’ve been working to resolve this for hours with no success and would greatly appreciate any help or suggestions from the community.
Moreover, if these issues can be resolved, I believe adding this Russian dictionary to currenctly supported English, German and French to Pleco by default would greatly benefit users from Central Asia, Eastern Europe, and Russia, given the dictionary's extensive entry count of 228,000 and given that these regions are all very accustomed to Russian language.
Thank you in advance for your assistance!
Best regards,
Kasim
I am experiencing difficulties with importing the BKRS dictionary (the largest Chinese-Russian dictionary available) into the Pleco app and am hoping for some guidance. Here’s a breakdown of the issues and my setup:
1. Dictionary Structure and Import Settings(Settings before importing 1; 2.PNG, BKRS Sample Text.PNG, Settings that I have no clue what they change.PNG):
The BKRS file is structured with fields for Chinese characters, Pinyin, and definitions in Russian. From my attempts, I understand that the first field for Chinese characters should be set to ‘Simplified’, and the second field for Pinyin should be set as ‘Mandarin’. However, I encountered a problem with making the Russian definitions searchable. Initially setting the third field to ‘English’ didn't allow searches in Russian. Changing the setting to ‘Entry body' made it searchable but led to display issues across devices.
2. Display Inconsistencies Across Devices (3 screenshots - Display Inconsistencies iPad, iPad 2, iPhone):
When I configure the output to 'entry body', the dictionary appears differently on my devices. On my iPhone, dictionary entries show up as empty(), and on my iPad, Russian definitions incorrectly appear as Pinyin. It seems there may be a misinterpretation or mishandling of the data.
3. Potential Bugs with Column Settings:
I've noticed potential bugs in how settings are managed within the app. For example, changing the setting 'split to second field' resets previous settings for the columns back to default. Additionally, under 'output to field' set to Mandarin, the 'parse as' options for tone numbers and symbols seem to be reversed: selecting tone marks displays numbers and vice versa.
I am also including a video and screenshots of my settings to better illustrate these issues. I am also sending an extract from the dictionary for you guys to see whether the file is corrupted or has formatting issues(whole file is too big to upload on a website). I’ve been working to resolve this for hours with no success and would greatly appreciate any help or suggestions from the community.
Moreover, if these issues can be resolved, I believe adding this Russian dictionary to currenctly supported English, German and French to Pleco by default would greatly benefit users from Central Asia, Eastern Europe, and Russia, given the dictionary's extensive entry count of 228,000 and given that these regions are all very accustomed to Russian language.
Thank you in advance for your assistance!
Best regards,
Kasim
Attachments
-
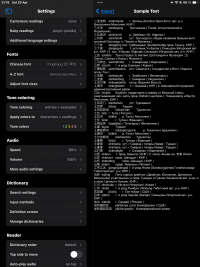 BKRS Sample Text.PNG524.4 KB · Views: 221
BKRS Sample Text.PNG524.4 KB · Views: 221 -
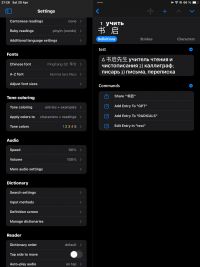 Display Inconsistencies - iPad 2.PNG247.1 KB · Views: 216
Display Inconsistencies - iPad 2.PNG247.1 KB · Views: 216 -
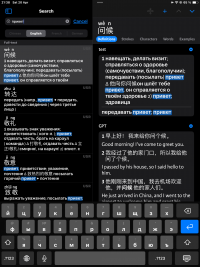 Display Inconsistencies - iPad.PNG608.2 KB · Views: 209
Display Inconsistencies - iPad.PNG608.2 KB · Views: 209 -
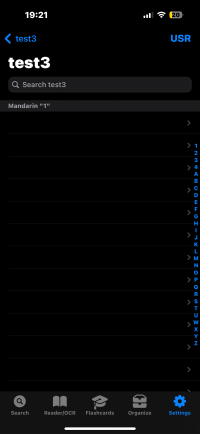 Display Inconsistencies - iPhone.PNG171 KB · Views: 212
Display Inconsistencies - iPhone.PNG171 KB · Views: 212 -
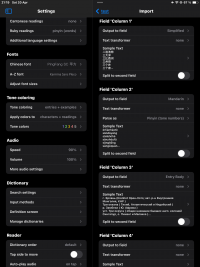 Settings before importing 1.PNG320.3 KB · Views: 232
Settings before importing 1.PNG320.3 KB · Views: 232 -
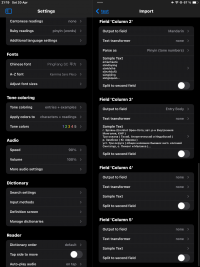 Settings before importing 2.PNG325.5 KB · Views: 214
Settings before importing 2.PNG325.5 KB · Views: 214 -
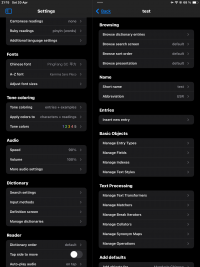 Settings that I have no clue what they change.PNG293 KB · Views: 213
Settings that I have no clue what they change.PNG293 KB · Views: 213 -
extract from BKRS.txt20.4 KB · Views: 242
