Shun
状元
Hello Mike,
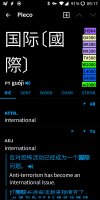
it occurred to me that it may be worthwhile to add an indicator for the frequency of a word in the upper right corner of a dictionary definition using the frequency data in the BCC corpus, allowing the user to see at a glance how common a word is. The frequency information could be given either by means of some sophisticated index score between 1 and 100, or it could be given a colored level between one and six, for example—1 being the most common, and 6 being the least common. The BCC corpus seems to have pretty loose licensing terms.
Pleco already seems to be using frequency data to sort the search results. Adding them meaningfully to dictionary definitions would be even better, I believe. That is something which printed dictionaries can’t do. Of course, there should be a toggle in the dictionary settings to turn the frequency display off.
Do you think this would be a viable idea?
Regards,
Shun
it occurred to me that it may be worthwhile to add an indicator for the frequency of a word in the upper right corner of a dictionary definition using the frequency data in the BCC corpus, allowing the user to see at a glance how common a word is. The frequency information could be given either by means of some sophisticated index score between 1 and 100, or it could be given a colored level between one and six, for example—1 being the most common, and 6 being the least common. The BCC corpus seems to have pretty loose licensing terms.
Pleco already seems to be using frequency data to sort the search results. Adding them meaningfully to dictionary definitions would be even better, I believe. That is something which printed dictionaries can’t do. Of course, there should be a toggle in the dictionary settings to turn the frequency display off.
Do you think this would be a viable idea?
Regards,
Shun
") ).
).