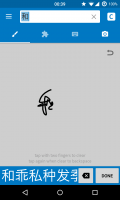
I was just about to reinstall Pleco anyway, so before removing it I deactivated all my purchases and went back to the basic handwriting recognizer just to check again. Still, I really can't seem to be able to write 和 in such a way that it doesn't get recognized: even if I never lift my finger and draw everything in one go, and even if it's totally illegible (see screenshot), I always get it as the first or, at the very least, second match. So I guess I can't really help you with your question directly.
But if you want some unsolicited advice from a fellow Chinese learner, it's really a good idea to follow the proscribed stroke order. There are several advantages: it'll help you memorize the characters faster, you'll be able to see through the complex ones more quickly and notice the patterns even if you didn't know them beforehand, and it'll be easier to learn the new ones as well. Being familiar with the stroke order is the make or break factor when trying to read handwriting. Most importantly, it's almost always the fastest way to write.
Sometimes there's some discretion as to the stroke order, but that's not the case here. Since you're learning it (I'm assuming), why not just learn it the proper way right from the start? Even if you can get 和 starting from the left, you'll run into problems with some other character (I'm guessing 夭: you'll be getting 天).
I get for instance 你, 机, 相,租
You should be getting 10 suggestions if I'm right, have you tried scrolling past the first few? Maybe 和 is still there somewhere farther? Also, are the suggestions consistently the same, or just seem random and different every time?
For me, in a handwrirting recognition system, the direction of one stroke should be a much less important than the number and position of strokes, and less important than the final shape of the character.
Actually, it's totally the opposite, at least for Chinese. It doesn't matter what the final result looks like, as long as you keep the stroke order right. The opening stroke is particularly important, it pretty much decides everything, the last ones can usually be skipped altogether in the case of more complex characters. Here, I start seeing 和 as a result without even doing the last 3 strokes.
It might help to understand how the handwriting recognition works. Basically, every character can be written as a series of strokes it is composed of. For example, 木 is (h, s, p, n) [for 橫、豎、撇、捺] and this actually distinguishes it uniquely from all the others: even 朩 would be (h, s, p, d) [for 點]. When you're writing, what the recognizer does is (mainly) to convert your hand movements to a series of standard strokes and then look for the closest match in its character database, with some tolerance for errors. So the most important thing is to only do the exact number of strokes necessary, definitely not more. From my experience, how the strokes are positioned spatially is of secondary importance.
Plus, you also need to consider two other things:
- Handwriting recognition is for people who know how to write characters, and these people generally write them following the standard stroke order, which allows them to write fast. If there was too much ambiguity allowed, it would basically mean disregarding the writer's stroke order, which conveys a lot of important information. Then, handwriting recognition would become just like OCR and there would be too many mismatches when the stroke order was adhered to (as this information would be excluded from consideration). In the end, this would annoy the principal group of its users.
- Strict recognition algorithm is actually an advantage if you use the handwriting module for flashcard practice. Otherwise, even when you don't really remember the character, you can "cheat" and draw something vaguely similar (your best guess), and the actual character would then probably appear as one of the matches.
I'd say the handwriting recognition in Pleco is actually pretty good (from my point of view, at least). Sorry I couldn't exactly pinpoint when the issue is but if I were you and couldn't get a character recognized, I'd actually take it as a hint that I need to reconsider the way I'm writing it (unless the character is very obscure, then maybe it just isn't in the database).